|
Nicholas Moratelli I'm a final-year PhD Student in Artificial Intelligence Engineering at AImageLab research group under the supervision of Prof. Rita Cucchiara. My research primarily focuses on Multimodal Large Language Models, Vision-and-Language Foundation Models and Retrieval-Augmented Generation. My research is driven by a deep interest in Generative AI and HPC systems.I leverage advanced AI technologies to lead innovative solutions, tackling both emerging and enduring challenges with adaptability and expertise. Previously, I received my Master’s Degree cum laude with a thesis entitled "Generating Natural Language Description by retrieving knowledge on large scale datasets through a novel attention operator", developed during a research internship.
Email /
CV /
Bio /
|

|
 Scholar
Scholar
 Linkedin
Linkedin
 GitHub
GitHub
 HuggingFace
HuggingFace
ResearchMy research interests include Computer Vision, Natural Language Processing, and Generative AI. The following is a list of the research projects I have developed. |

|
LLaVA-MORE Enhancing Visual Instruction Tuning with LLaMA 3.1
Federico Cocchi, Nicholas Moratelli, Davide Caffagni, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara Technical Report, 2024 project page LLaVA-MORE enhances the well-known LLaVA architecture by integrating for the first time the use of LLaMA 3.1 as the language model. |
|
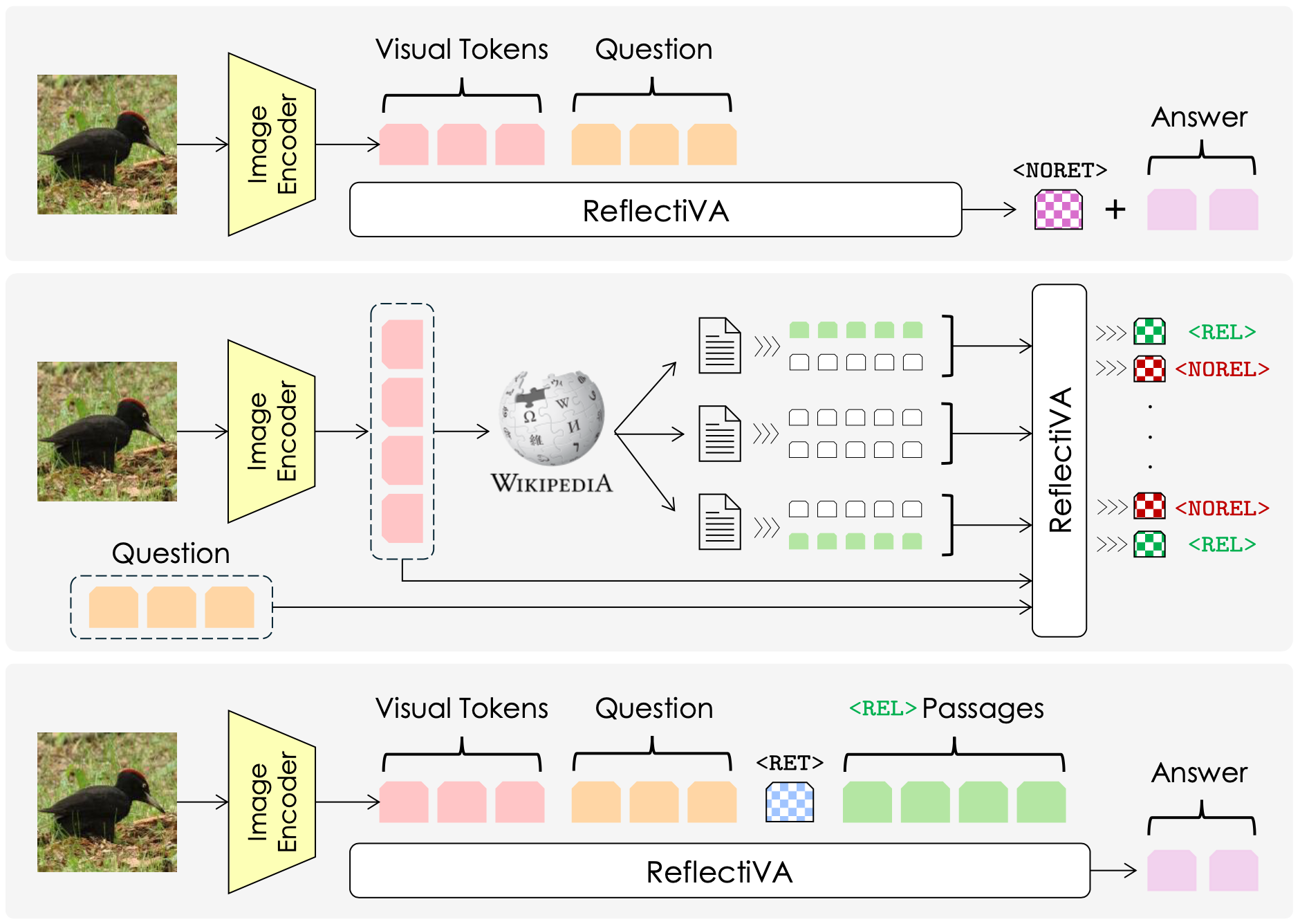
Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering
Federico Cocchi*, Nicholas Moratelli*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara Conference on Computer Vision and Pattern Recognition, CVPR 2025 🇺🇸 paper / code In this work, we introduce a novel method to enhance the adaptability of MLLMs by integrating external knowledge sources. Our proposed model, Reflective LLaVA (ReflectiVA), utilizes reflective tokens to dynamically determine the need for external knowledge and predict the relevance of information retrieved from an external database. Tokens are trained following a two-stage two-model training recipe. |
|
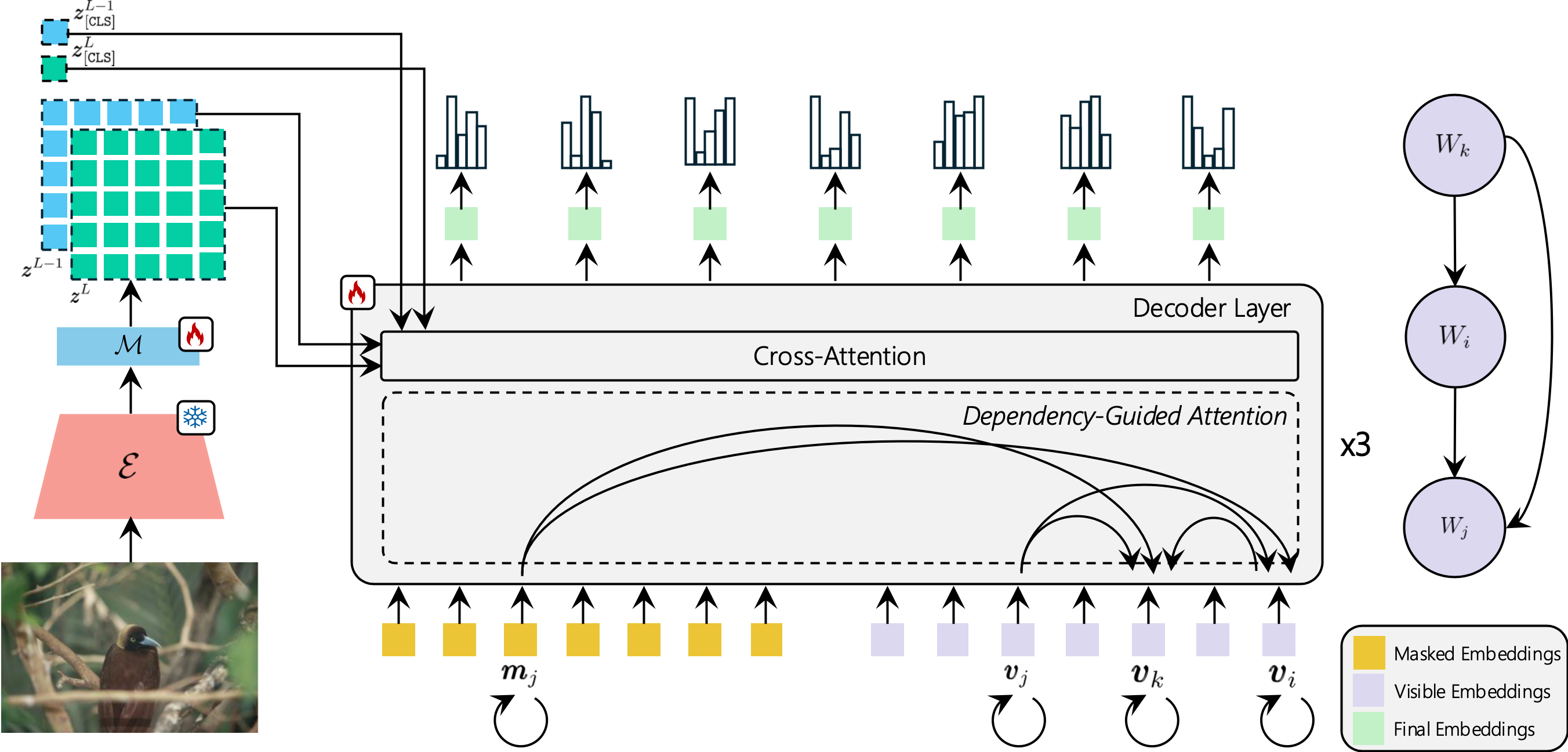
Causal Graphical Models for Vision-Language Compositional Understanding
Fiorenzo Parascandolo, Nicholas Moratelli, Enver Sangineto, Lorenzo Baraldi, Rita Cucchiara International Conference on Learning Representations, ICLR 2025 🇸🇬 paper / project / code In this paper, we model the dependency relations among textual and visual tokens using a Causal Graphical Model (CGM), built using a dependency parser, and we train a decoder conditioned by the VLM visual encoder. Differently from standard autoregressive or parallel predictions, our decoder’s generative process is partially-ordered following the CGM structure. |
|
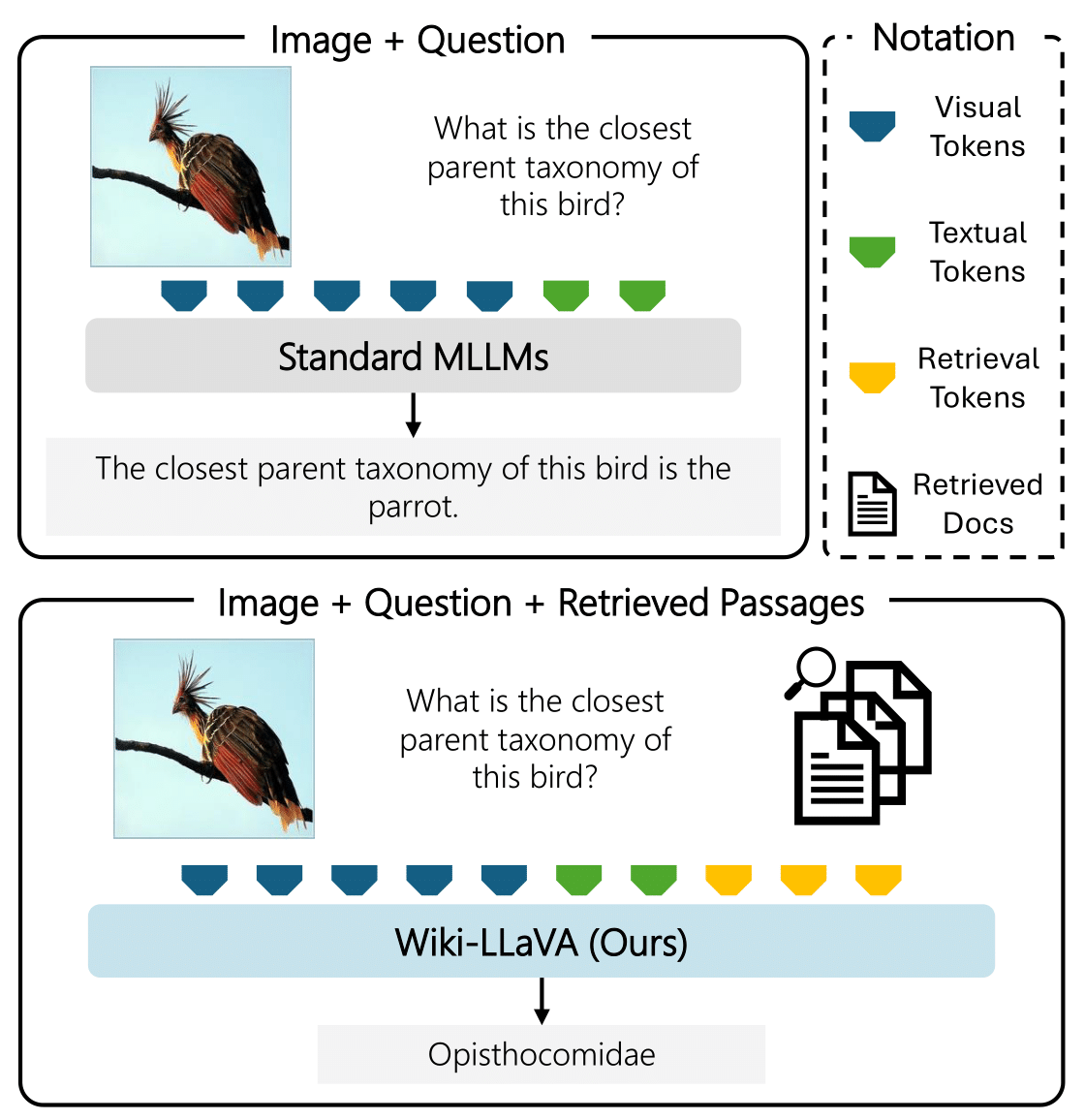
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Davide Caffagni*, Federico Cocchi*, Nicholas Moratelli*, Sara Sarto*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara Conference on Computer Vision and Pattern Recognition, CVPR Workshop 2024 🇺🇸 paper In this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. |
|
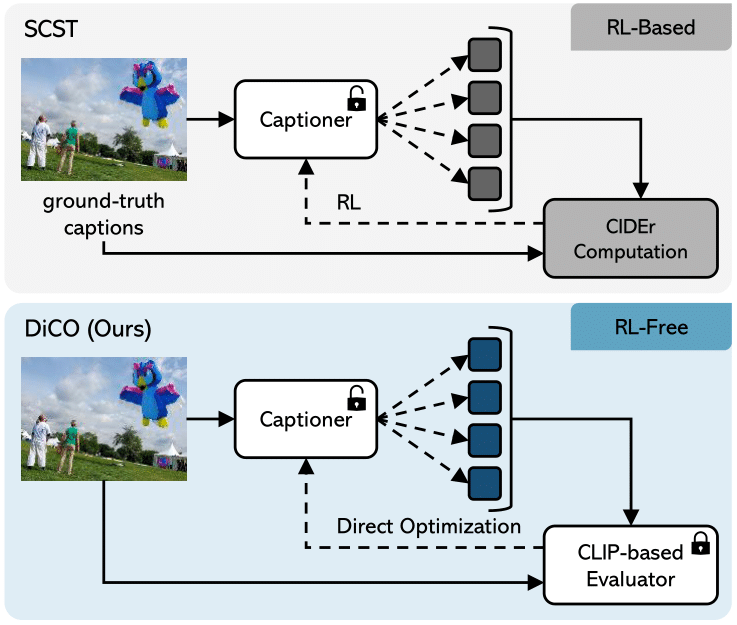
Revisiting Image Captioning Training Paradigm via Direct CLIP‑based Optimization
Nicholas Moratelli*, Davide Caffagni*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara British Machine Vision Conference, BMVC 2024 🏴 [ ORAL ] paper / code In this paper, we propose a new training paradigm termed Direct CLIP-Based Optimization. Our approach jointly learns and optimizes a reward model that is distilled from a learnable captioning evaluator with high human correlation. This is done by solving a weighted classification problem directly inside the captioner. At the same time, DiCO prevents divergence from the original model, ensuring that fluency is maintained. |
|
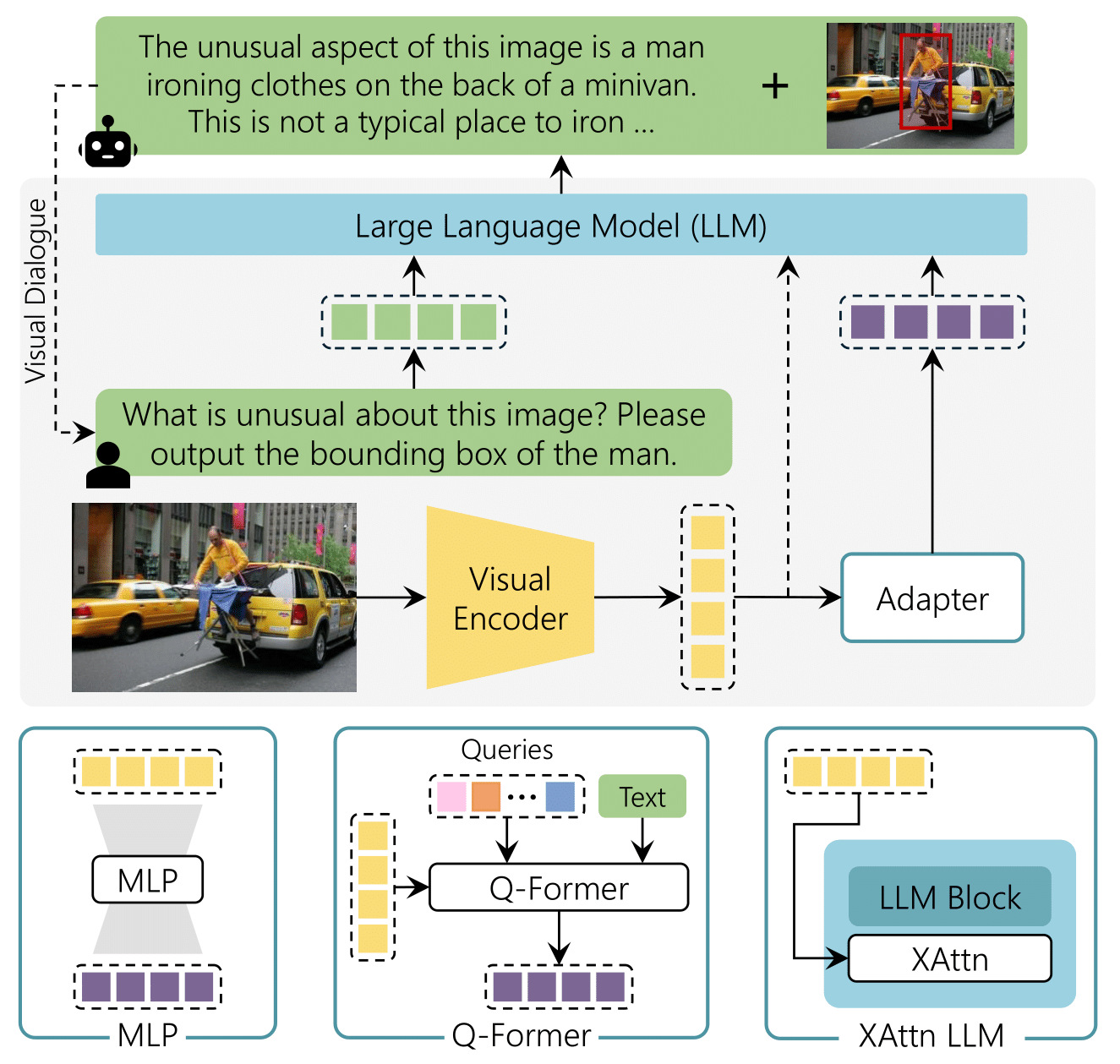
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni*, Federico Cocchi*, Luca Barsellotti*, Nicholas Moratelli*, Sara Sarto*, Lorenzo Baraldi*, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara Association for Computational Linguistics, ACL Findings 2024 🇹🇭 paper In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. |
|
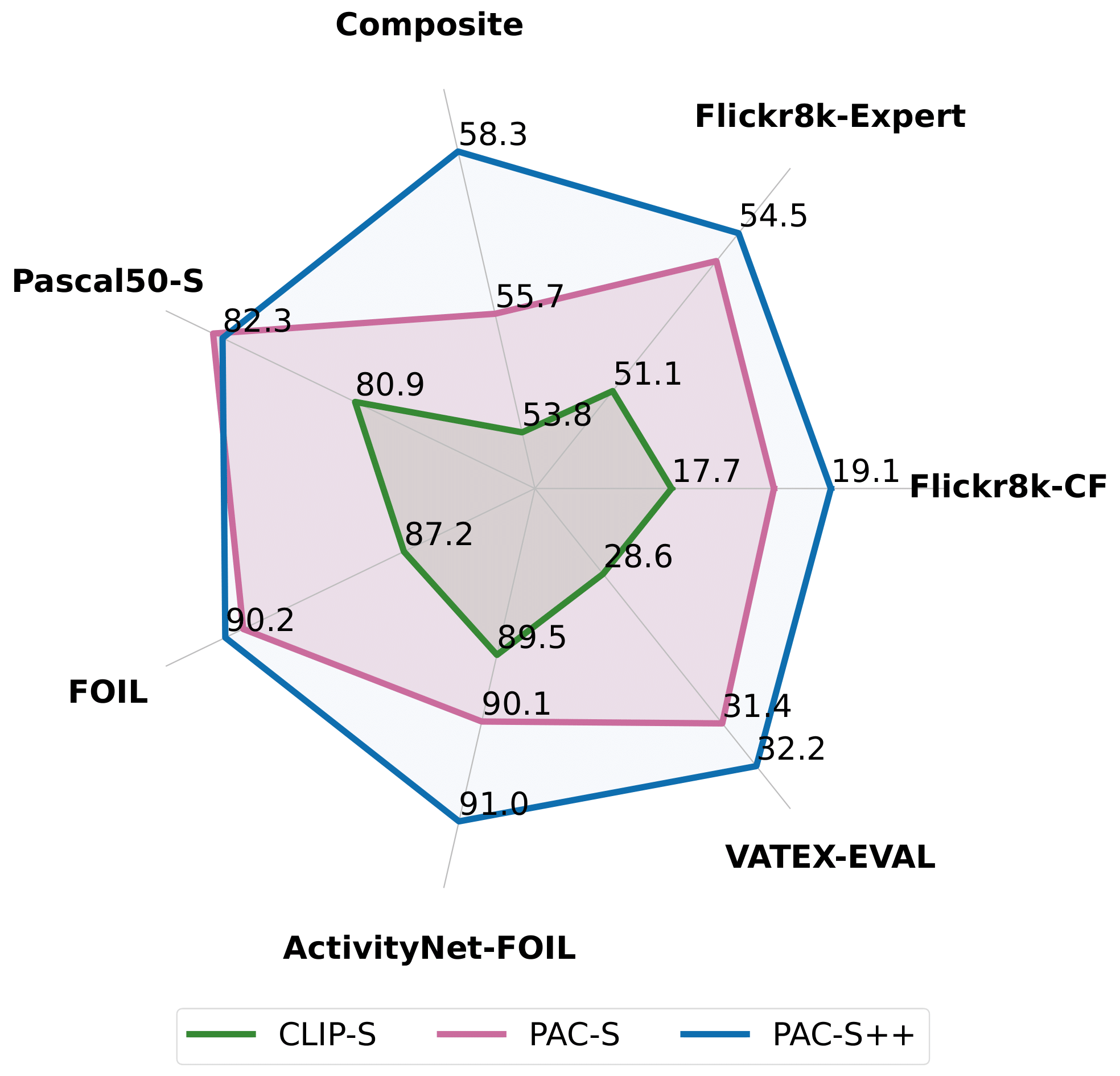
Positive-Augmented Contrastive Learning for Vision-and-Language Evaluation and Training
Sara Sarto*, Nicholas Moratelli*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara Under review at a top tier journal paper / code In this paper, we propose PAC-Score++, a learnable metric that leverages the CLIP model, pre-trained on both web-collected and cleaned data, and regularized through additional pairs of generated visual and textual positive samples. Exploiting this stronger and curated pre-training, we show that integrating PAC-Score++ into a captioner fine-tuning stage results in semantically richer captions with fewer repetitions and hallucinations. |
|
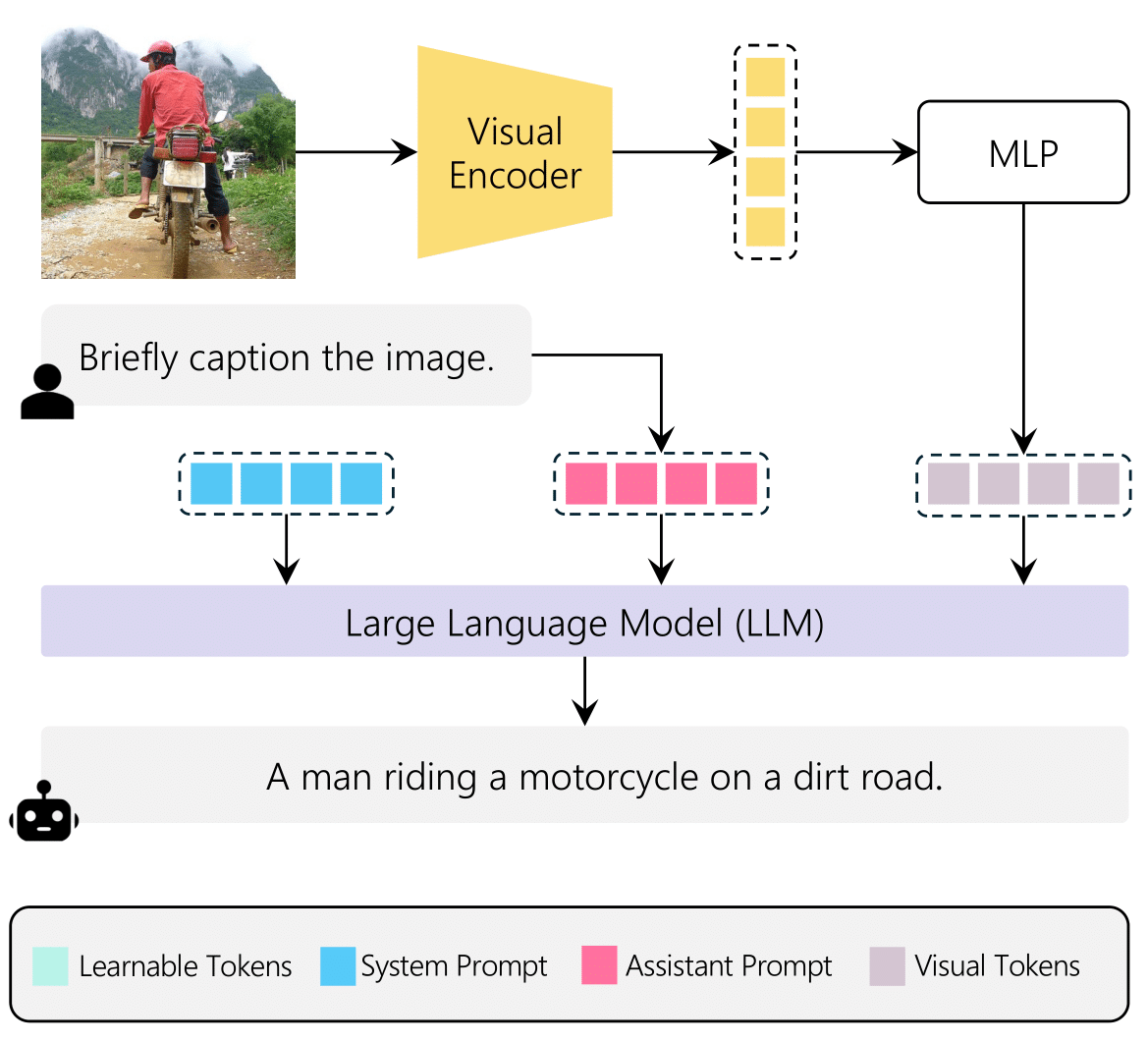
Personalizing Multimodal Large Language Models for Image Captioning: An Experimental Analysis
Davide Bucciarelli, Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara European Conference on Computer Vision and Pattern Recognition, ECCV Workshop 2024 🇮🇹 paper This paper investigates whether Multimodal LLMs can supplant traditional image captioning networks by evaluating their performance on various image description benchmarks. We explore both the zero-shot capabilities of these models and their adaptability to different semantic domains through fine-tuning methods, including prompt learning, prefix tuning, and low-rank adaptation. |
|
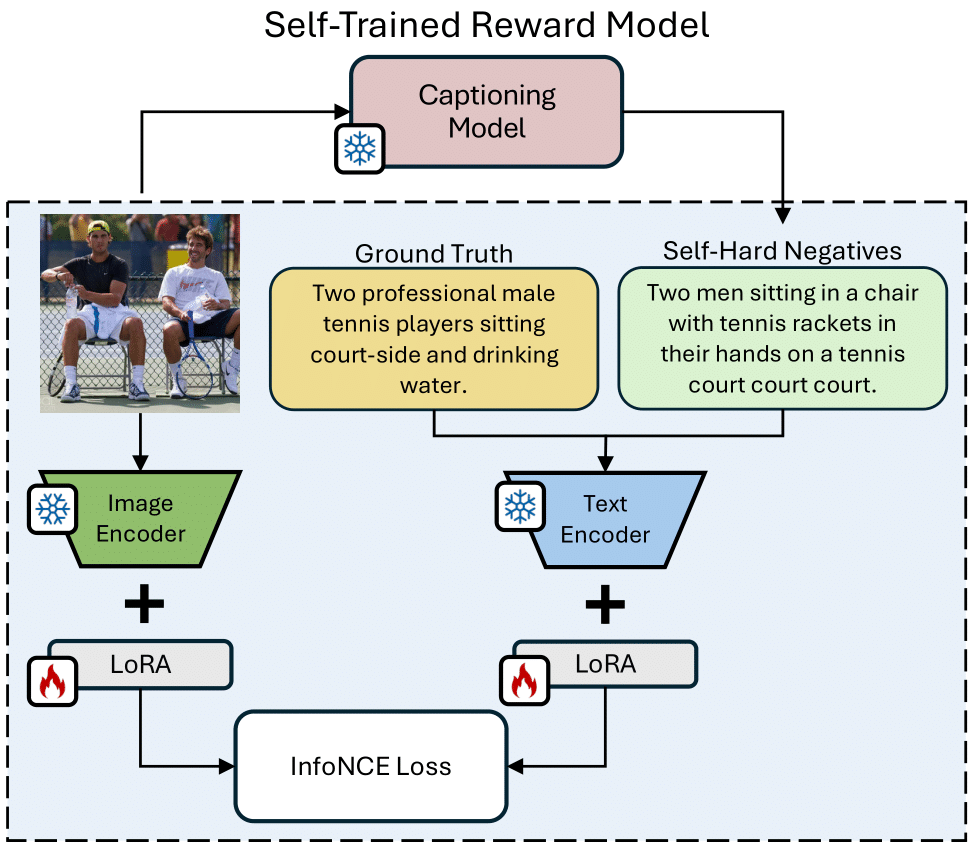
Fluent and Accurate Image Captioning with a Self-Trained Reward Model
Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara International Conference on Pattern Recognition, ICPR 2024 🇮🇳 [ ORAL ] paper In this paper, we propose Self-Cap, a captioning approach that relies on a learnable reward model based on self-generated negatives that can discriminate captions based on their consistency with the image. Specifically, our discriminator is a fine-tuned contrastive image-text model trained to promote caption correctness while avoiding the aberrations that typically happen when training with a CLIP-based reward. |
|
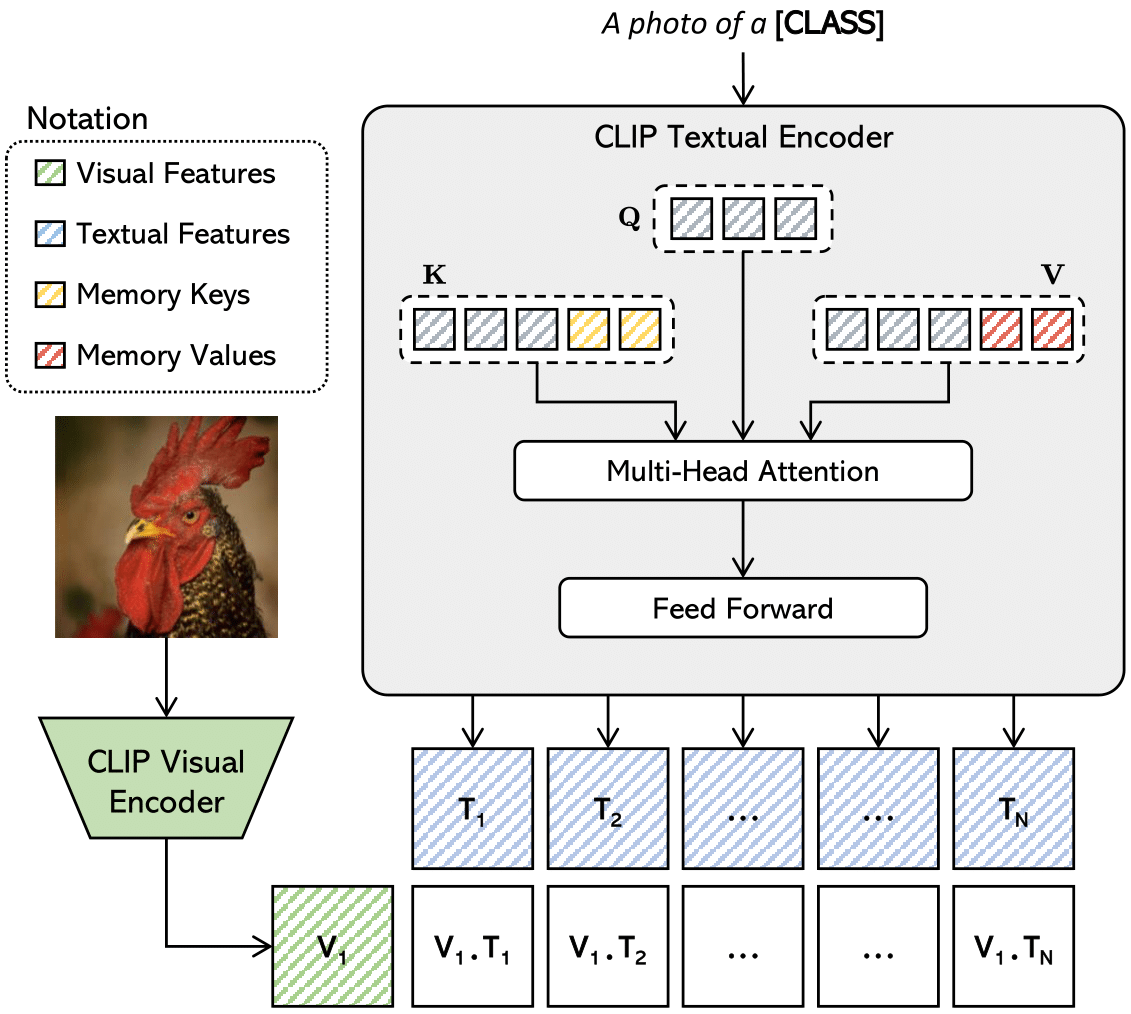
Are Learnable Prompts the Right Way of Prompting? Adapting Vision-and-Language Models with Memory Optimization
Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara IEEE Intelligent Systems, 2024 paper The effectiveness and expressive power of prompts are limited by the fact that they can only lie at the input of the architecture. In this paper, we critically question the usage of learnable prompts, and instead leverage the concept of "implicit memory" to directly capture low- and high-level relationships within the attention mechanism at any layer of the architecture, thereby establishing an alternative to prompts in FSL. |
|
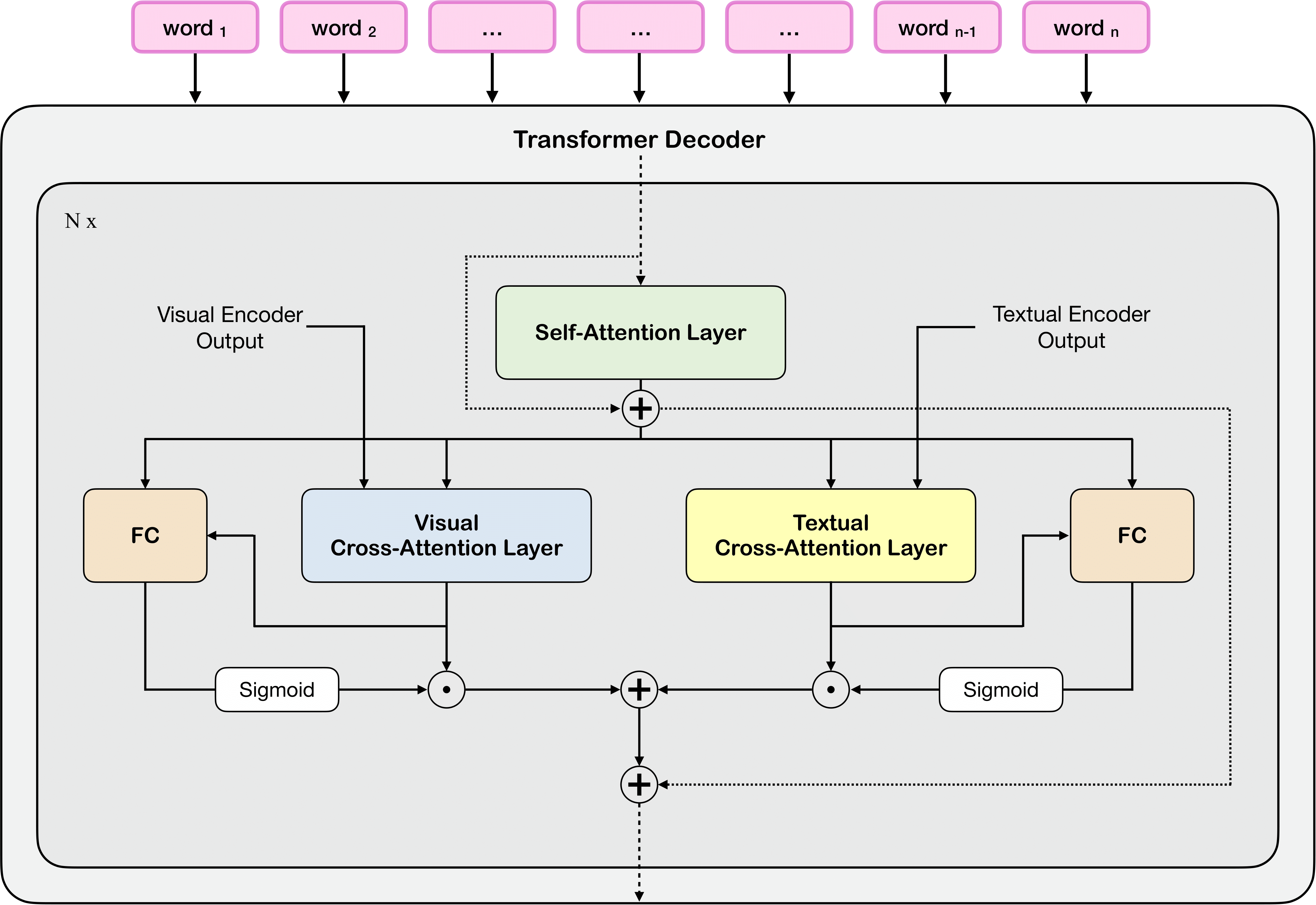
Fashion-oriented image captioning with external knowledge retrieval and fully attentive gates
Nicholas Moratelli, Manuele Barraco, Davide Morelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara Sensors MDPI, 2023 paper This article tackles the task of generating fine-grained and accurate natural language descriptions of fashion items, a recently-proposed and under-explored challenge that is still far from being completely solved. We developed a Transformer model capable of reading and retrieving items from external memory through cross-attention operations, regulating the flow of information from the external memory using a novel fully-attentive gate. |
Participation to National and European Projects |
|
FAIR - Future Artificial Intelligence Research
FAIR project aims to help address the research questions, methodologies, models, technologies, and even ethical and legal rules for building Artificial Intelligence systems capable of interacting and collaborating with humans. I'm involved in the Transversal Project on Visual, Language and Multimodal Challenge (VLMC). |
|
|
MUCES - Platform for Content Enrichment and Search in Audiovisual Archives
PRIN MUCES is a project committed to the development, training, and public release of fully multimodal foundation models. I am involved in the project as a PhD student, where I work on the creation of Multimodal Large Language Model with content-based retrieval capabilities on a large scale. |
Academic Service |
- European Conference on Computer Vision, ECCV 2024
- British Machine Vision Conference, BMVC 2024
- International Conference on Pattern Recognition, ICPR 2024
- International Conference on ACM Multimedia, ACM MM 2023
- Pattern Recognition Letters
|
Website created by Nicholas | HTML template from Jon Barron |